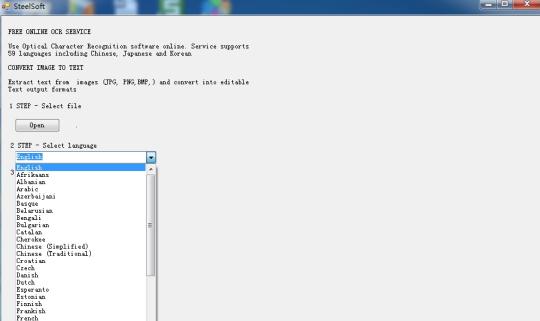
Reconnaître le texte à partir d'images en utilisant le moteur Tesseract OCR basé sur la technologie de cloud.
Utilisez un logiciel de reconnaissance de caractères en ligne. Service prend en charge 59 langues, dont le chinois, le japonais et le coréen. Extrait du texte à partir d'images (JPG, PNG, BMP, TIF) et de convertir en formats de sortie de texte modifiable.
Il est basé sur la technologie cloud, et très célèbre moteur OCR (Tesseract OCR Engine), donc il est à seulement quelques centaines de KB en taille, mais il peut extraire du texte dans 59 langues, à partir des images.
Il prend en charge plusieurs langues: bulgare, catalan, tchèque, danois, néerlandais, anglais, finnois, français, allemand, grec, hongrois, indonésien, italien, letton, lituanien, norvégien, polonais, portugais, roumain, russe, serbe, slovaque, slovène , espagnol, suédois, tagalog, turc, ukrainien, vietnamien, etc.
Quoi de neuf dans cette version:..
La version 5.0 comprend des améliorations UE

Commentaires non trouvées