
PDF Extractor SDK pour les développeurs de logiciels Windows: PDF à texte, PDF à XML, Images à partir de PDF, Lire des informations PDF, PDF à CSV pour Excel.
Bytescout PDF Extractor SDK permet de convertir des fichiers PDF en texte, PDF en XML, PDF en CSV, extraire des images à partir de PDF, extraire des informations sur les fichiers PDF dans les interfaces .NET et ActiveX sans aucun logiciel supplémentaire requis.
Avantages:
convertit le PDF en texte brut (et peut suivre les colonnes si vous convertissez un journal au format PDF) - y compris l'extraction de texte invisible;
convertit les tableaux en PDF en Excel (CSV) en lisant les cellules d'un rectangle donné;
convertit les tableaux en PDF en fichiers XML;
extraire les métadonnées du fichier PDF (titre, auteur, description) et obtenir d'autres informations sur le fichier (nombre de pages, chiffrées ou non);
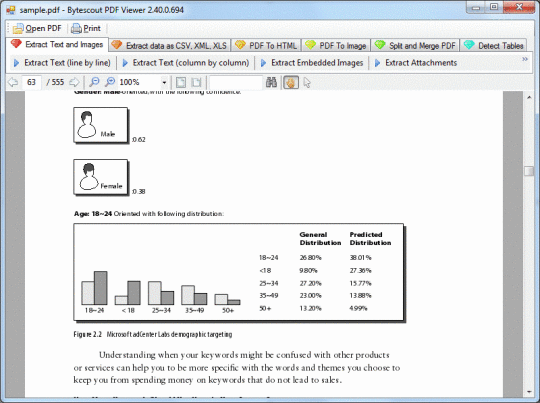
extrait des images incorporées à partir d'un document PDF (dans ASP.NET, VB.NET, C #, VB6 et VBScript);
Interfaces et classes DocumentMerger et DocumentSplitter pour fusionner et diviser des documents PDF;
ne nécessite pas Adobe Reader ou tout autre logiciel de lecture de PDF à installer;
fournit des interfaces .NET et ActiveX;
faite avec du code C # géré à 100%.
Nouveautés dans cette version:
Version 9.0.0.3079: Ajout du filtrage du contenu extrait par nom de police, taille de police et couleur.
Mise à jour du moteur OCR vers la dernière version. Mettre à jour les fichiers de langue du dossier 'tessdata'.
Extraction de texte améliorée, regroupement de lignes sous forme de données tabulaires, performances, extraction de formulaires XFA, TableDetector, problèmes d'analyse de fichiers PDF fixes.
Nouveautés dans la version 8.7.0.2980:
Ajout du filtrage du contenu extrait par nom de police, taille de police et couleur.
Mise à jour du moteur OCR vers la dernière version. Mettre à jour les fichiers de langue du dossier 'tessdata'.
Extraction de texte améliorée, regroupement de lignes en données tabulaires, performances, extraction de formulaires XFA, TableDetector, problèmes d'analyse de fichiers PDF fixes.
Nouveautés dans la version 8.6.0.2911:
Ajout du filtrage du contenu extrait par nom de police, taille de police et couleur.
Mise à jour du moteur OCR vers la dernière version. Mettre à jour les fichiers de langue du dossier 'tessdata'.
Extraction de texte améliorée, regroupement de lignes en données tabulaires, performances, extraction de formulaires XFA, TableDetector, problèmes d'analyse de fichiers PDF fixes.
Nouveautés dans la version 8.2.0.2699:
La version 8.2.0.2699 peut inclure des mises à jour, des améliorations ou des corrections de bogues non spécifiées.
Nouveautés dans la version 8.0.0.2528:
Nouveautés dans la version 7.0.0.2474:
Version 7.0.0.2474:
- ajout d'une nouvelle classe d'utilitaire DocumentPrinter permettant d'imprimer des documents PDF en mode silencieux (sans boîte de dialogue utilisateur)
- ajout d'une nouvelle classe JSONExtractor
- ajout d’une substitution pour la méthode DocumentSplitter.Split () permettant de spécifier le dossier de sortie des fichiers générés
- correction d’un bogue multi-thread dans DocumentSplitter
- tableDetector respecte maintenant la zone d'extraction définie par la méthode SetExtractionArea ()
- nouvelles propriétés dans les classes d’extraction: ExtractionColumns - contient les coordonnées des colonnes détectées; CustomExtractionColumns - permet de remplacer la détection de colonne
- Les méthodes GetPageRect * ne prenaient pas en compte la rotation des pages.
Correction d'un bug dans l'installateur causant des fichiers de l'installation précédente interférer avec les mises à jour - retravaillé la vérification des inscriptions. Maintenant, la bibliothèque ne lancera pas d'exception, mais fonctionnera en mode démo si vous avez manqué ou saisi un mauvais nom d'enregistrement et une clé d'enregistrement.
- Multitool PDF: ajout de la liste des documents récents au bouton "Ouvrir un document PDF"
- Multitool PDF: la sélection peut être redimensionnée maintenant
- Multitool PDF: ajout de la fonctionnalité JSON d'extraction
- Multitool PDF: amélioration de l'interface utilisateur du détecteur de table
- Multitool PDF: qualité de rendu des polices grandement améliorée
- Multitool PDF: Option de débogage "Afficher les colonnes d'extraction détectées" dans le menu contextuel pour afficher les colonnes détectées sur la page en cours. Ne devient visible qu'après avoir exécuté une extraction sur la page actuellement affichée
- Multitool PDF: correction du problème de rendu des polices sur Windows 32 bits
- autres améliorations mineures et corrections de bugs
Nouveautés dans la version 6.30.0.2421:
Version 6.30.0.2421:
- Ajout de la classe d'utilitaire TextComparer (disponible uniquement dans les assemblys .NET 4.0) permettant de comparer du texte dans deux documents PDF et de générer des rapports.
- Prise en charge améliorée des profils de couleur ICC.
- Gestion des polices incorporées améliorée.
- Amélioration de AttachmentExtractor.
- Correction de la méthode XMLExtractor.SaveXMLToStream ().
- Correction de la duplication de texte extraite lors de l’utilisation de l’option OCRCacheMode.WholePage.
- Autres corrections de bogues et améliorations.
Nouveautés dans la version 6.20.2354:
Version 6.20.2354:
- PDF To Text, PDF à CSV, fonctions PDF à XML améliorées
- Nouveaux extraits vidéo, extraits audio
- Les extracteurs CSV et XML ont amélioré la prise en charge des tableaux contenant des colonnes vides à l'intérieur
- nouveau MultimediaExtractor pour extraire la vidéo et l’audio du PDF
- nouvelle propriété PageDataCaching
- nouvel exemple "MemoryCareProcessingOfHugeFiles"
- correction d'une exception null lors de la tentative d'élimination des pages déjà éliminées
- XLSExtractor: améliore la prise en charge des polices
- SkipInvisibleText ignore maintenant le texte tronqué (qui n'est pas visible)
- rendu de la sortie du texte amélioré
- Extracteur XFDF: prise en charge des cases à cocher
- La sortie des images a été améliorée pour prendre en charge plus de sous-formats
- Amélioration de la gestion du texte Unicode
Nouveautés dans la version 6.11.2149:
Version 6.11.2149:
- Exemples de traitement par lots mis à jour pour montrer l'utilisation de la méthode Reset ()
- Exemple de code source C ++ ajouté pour l'extraction de pages
- DocumentMerger ajoute la méthode Merge2 (inputfile1, inputfile2, outputfile) pour fusionner 2 fichiers
- Corrections de bogues mineures de XLS Extractor
- L'outil multifonction PDF permet désormais d'activer / désactiver le texte, l'image, les calques vectoriels, ajoute des paramètres avancés pour l'extraction de texte
- XML, CSV, extraction de table améliore la prise en charge des tables contenant des cellules emtpry dans les colonnes
- La propriété .ExtractShadowLikeText a été améliorée: meilleur filtrage pour du texte de type ombre
Nouveautés dans la version 6.10.2136:
Version 6.10.2136:
- Amélioration de la fonctionnalité PDF vers XML, PDF vers CSV, PDF vers texte
- Exemple de ligne de commande PDF To XLS ajouté (basé sur vbscript)
- PDF To HTML SDK ajoute une nouvelle propriété .DetectHyperLinks (TRUE par défaut) pour activer / désactiver la détection automatique des liens dans le texte
- nouveau SearchablePDFMaker (disponible pour les licences PRO) pour convertir des fichiers PDF en fichiers PDF consultables
- nouvelles propriétés dans l'extracteur: ConsiderFontNames, ConsiderFontSizes, ConsiderFontColors, ConsiderVerticalBorders dans les fichiers CFG
- détection des colonnes d’en-tête (lorsque AutoAlighHeaderToColumns = true) améliorée
- .DetectLinesInsteadOfParagraphs remplacé par un nouveau .LineGroupingMode pour contrôler la manière dont les lignes sont fusionnées en paragraphes
- IMPORTANT! PDF To XML corrige un problème de longue durée avec une coordonnée Y incorrecte pour les objets texte (pointait vers le bas à gauche au lieu de haut à gauche)
Ajout des propriétés - .TableXMinIntersectionRequiredInPercents et .TableYMinIntersectionRequiredInPercents
- Exemple de code source C ++ ajouté
- XML Extractor corrige les colonnes vides manquantes dans PreserveFormatting = mode true
- corrections mineures en couleurs dans certains fichiers PDF
- prise en charge de plusieurs langues OCR ajoutées
- Interface utilisateur graphique Multitool PDF: ajoute le bouton Copier dans le Presse-papiers aux boîtes de dialogue TXT, CSV, XML et de rendu raster
- XLSExtractor: ajoute la propriété PageToWorksheet pour activer / désactiver la génération de feuilles de calcul séparées par page
- nouvelle propriété .TextEncodingCodePage
- PDFViewerControl: ajoute ValidateContextMenu permettant à l'utilisateur d'ajouter des éléments personnalisés au menu contextuel
- Contrôle PDF Viewer: ajoute les propriétés ShowTextObjects, ShowImageObjects, ShowVectorObjects
- XMLExtractor ajoute maintenant l'attribut "OCRConfidence" pour le texte reconnu
- Fonctionnalité de vérification PDF / A (en version bêta)
- améliorer les contrôles et la vérification et l’alignement du texte en fonction de la mise en page originale. Le problème était dû au décalage des coordonnées Y dans les contrôles lors de l'analyse: cela était incorrect. La manière correcte est de shif ...
- XML Extractor a été mis à jour: produit désormais une balise CONTROL pour les cases à cocher et les champs de texte
- utilisation du répertoire courant dans le répertoire temporaire
- les cases à cocher, radiobox, editboxes, combobox sont mieux supportées
- permet désormais aux appelants de confiance partielle
Nouveautés dans la version 5.80.1781:
Version 5.80.1781:
- Mise à jour des fonctionnalités PDF vers XML, PDF vers CSV, PDF vers texte
- OCRMode fournit maintenant 9 modes
- .DetectLineInsteadOfParagraph fonctionne désormais beaucoup mieux. Définissez-le sur False pour capturer le texte multiligne dans les cellules de tableau!
- La prise en charge des contrôles PDF est améliorée
- Extraction de données FDF et XFDF
Nouveautés dans la version 5.10.1747:
Version 5.10.1747:
- Amélioration des fonctions PDF vers XML, PDF vers CSV, PDF vers texte
- prend désormais en charge l'extraction de texte à partir des contrôles de texte
- L’extracteur XML ajoute désormais le style de police, la taille, le nom et les coordonnées du texte dans les balises
- Ajout de l'exemple ASP.NET pour l'utilisation de l'OCR
- nouvelle propriété OCRLanguageDataFolder pour spécifier l'emplacement du dossier "tessdata"
- Amélioration du support des fichiers PDF
- améliore la prise en charge du texte pivoté
- échantillons de code source mis à jour
- documentation mise à jour
- améliorations et corrections mineures
Nouveautés dans la version 5.00.1626:
Version 5.00.1626:
- OCR (texte à partir d’images): vous pouvez désormais extraire du texte à partir d’images incorporées et réparer le texte endommagé
- Problème résolu avec les extracteurs CSV et XML manquant les dernières colonnes avec certains paramètres
- Amélioration du support des fichiers PDF endommagés
- la recherche de texte de recherche multiligne avec les modes de correspondance de mots est maintenant prise en charge
- peut maintenant rechercher du texte avec des tirets et sur des lignes différentes: voir un nouvel exemple de code source Rechercher du texte avec des tirets
- nouvelle propriété .RTLTextAutoDetectionEnabled (false par défaut) pour détecter automatiquement les langues RTL
- Démo de l'interface graphique de PDF Viewer améliorée
- améliorations et corrections mineures
Ajout de la fonctionnalité
Configuration requise :
.NET Framework 2.0 ou supérieur
Limitations :
Écran Nag, filigrane sur la sortie
Commentaires non trouvées